Background Modeling
When fitting a spectrum with a background, it is invalid to simply subtract off the background if the background is part of the data’s generative model van Dyk et al. (2001). Therefore, we are often left with the task of modeling the statistical process of the background along with our source.
In typical spectral modeling, we find a few common cases when background is involved. If we have total counts (\(S_i\)) in \(i^{\rm th}\) on \(N\) bins observed for an exposure of \(t_{\rm s}\) and also a measurement of \(B_i\) background counts from looking off source for \(t_{\rm b}\) seconds, we can then suppose a model for the source rate (\(m_i\)) and background rate (\(b_i\)).
Poisson source with Poisson background
This is described by a likelihood of the following form:
which is a Poisson likelihood for the total model (\(m_i +b_i\)) conditional on the Poisson distributed background observation. This is the typical case for e.g. aperture x-ray instruments that observe a source region and then a background region. Both observations are Poisson distributed.
Poisson source with Gaussian background
This likelihood is similar, but the conditonal background distribution is described by Gaussian:
where the \(\sigma_{b,i}\) are the measured errors on \(B_i\). This situation occurs e.g. when the background counts are estimated from a fitted model such as time-domain instruments that estimate the background counts from temporal fits to the lightcurve.
In 3ML, we can fit a background model along with the the source model which allows for arbitrarily low background counts (in fact zero) in channels. The alternative is to use profile likelihoods where we first differentiate the likelihood with respect to the background model
and solve for the \(b_i\) that maximize the likelihood. Both the Poisson and Gaussian background profile likelihoods are described in the XSPEC statistics guide. This implicitly yields \(N\) parameters to the model thus requiring at least one background count per channel. These profile likelihoods are the default Poisson likelihoods in 3ML when a background model is not used with a SpectrumLike (and its children, DispersionSpectrumLike and OGIPLike) plugin.
Let’s examine how to handle both cases.
[1]:
import warnings
warnings.simplefilter("ignore")
import numpy as np
np.seterr(all="ignore")
[1]:
{'divide': 'warn', 'over': 'warn', 'under': 'ignore', 'invalid': 'warn'}
[2]:
%%capture
from threeML import *
[3]:
from jupyterthemes import jtplot
%matplotlib inline
jtplot.style(context="talk", fscale=1, ticks=True, grid=False)
set_threeML_style()
silence_warnings()
import astropy.units as u
First we will create an observation where we have a simulated broken power law source spectrum along with an observed background spectrum. The background is a powerl law continuum with a Gaussian line.
[4]:
# create the simulated observation
energies = np.logspace(1, 4, 151)
low_edge = energies[:-1]
high_edge = energies[1:]
# get a BPL source function
source_function = Broken_powerlaw(K=2, xb=300, piv=300, alpha=0.0, beta=-3.0)
# power law background function
background_function = Powerlaw(K=0.5, index=-1.5, piv=100.0) + Gaussian(
F=50, mu=511, sigma=20
)
spectrum_generator = SpectrumLike.from_function(
"fake",
source_function=source_function,
background_function=background_function,
energy_min=low_edge,
energy_max=high_edge,
)
spectrum_generator.view_count_spectrum()
[4]:
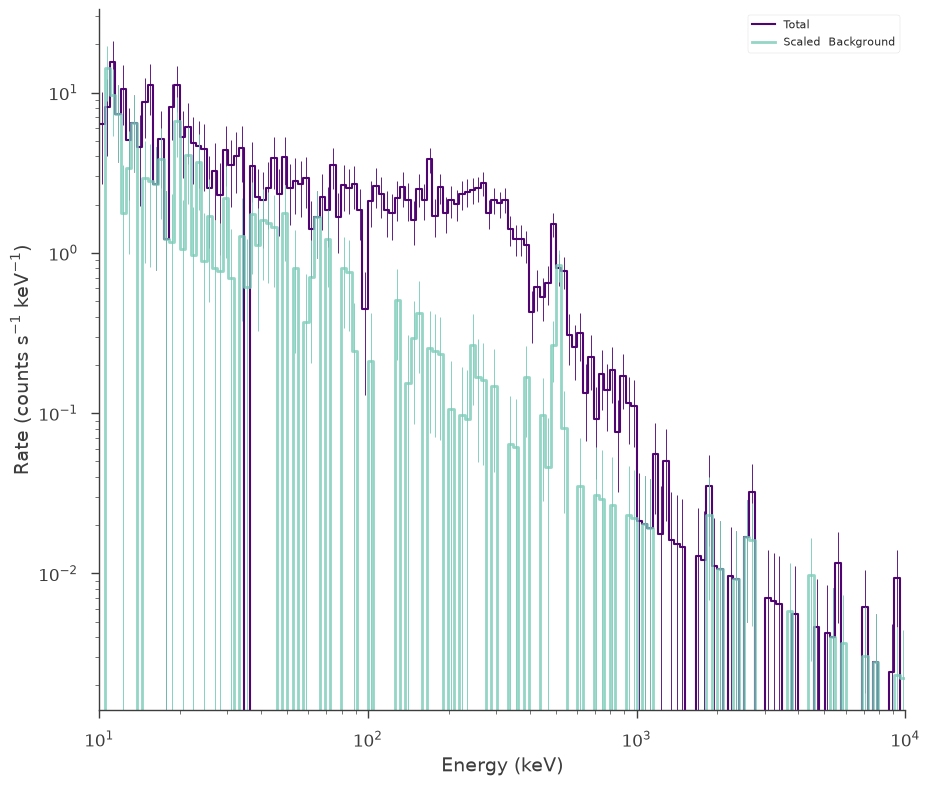

Using a profile likelihood
We have very few counts counts in some channels (in fact sometimes zero), but let’s assume we do not know the model for the background. In this case, we will use the profile Poisson likelihood.
[5]:
# instance our source spectrum
bpl = Broken_powerlaw(piv=300, xb=500)
# instance a point source
ra, dec = 0, 0
ps_src = PointSource("source", ra, dec, spectral_shape=bpl)
# instance the likelihood model
src_model = Model(ps_src)
# pass everything to a joint likelihood object
jl_profile = JointLikelihood(src_model, DataList(spectrum_generator))
# fit the model
_ = jl_profile.fit()
# plot the fit in count space
_ = spectrum_generator.display_model(step=False)
Best fit values:
| result | unit | |
|---|---|---|
| parameter | ||
| source.spectrum.main.Broken_powerlaw.K | 2.07 -0.14 +0.15 | 1 / (keV s cm2) |
| source.spectrum.main.Broken_powerlaw.xb | (3.06 -0.11 +0.12) x 10^2 | keV |
| source.spectrum.main.Broken_powerlaw.alpha | (-1 +/- 8) x 10^-2 | |
| source.spectrum.main.Broken_powerlaw.beta | -3.13 +/- 0.16 |
Correlation matrix:
| 1.00 | -0.64 | 0.78 | 0.02 |
| -0.64 | 1.00 | -0.50 | -0.54 |
| 0.78 | -0.50 | 1.00 | 0.01 |
| 0.02 | -0.54 | 0.01 | 1.00 |
Values of -log(likelihood) at the minimum:
| -log(likelihood) | |
|---|---|
| fake | 403.936044 |
| total | 403.936044 |
Values of statistical measures:
| statistical measures | |
|---|---|
| AIC | 816.147949 |
| BIC | 827.914628 |
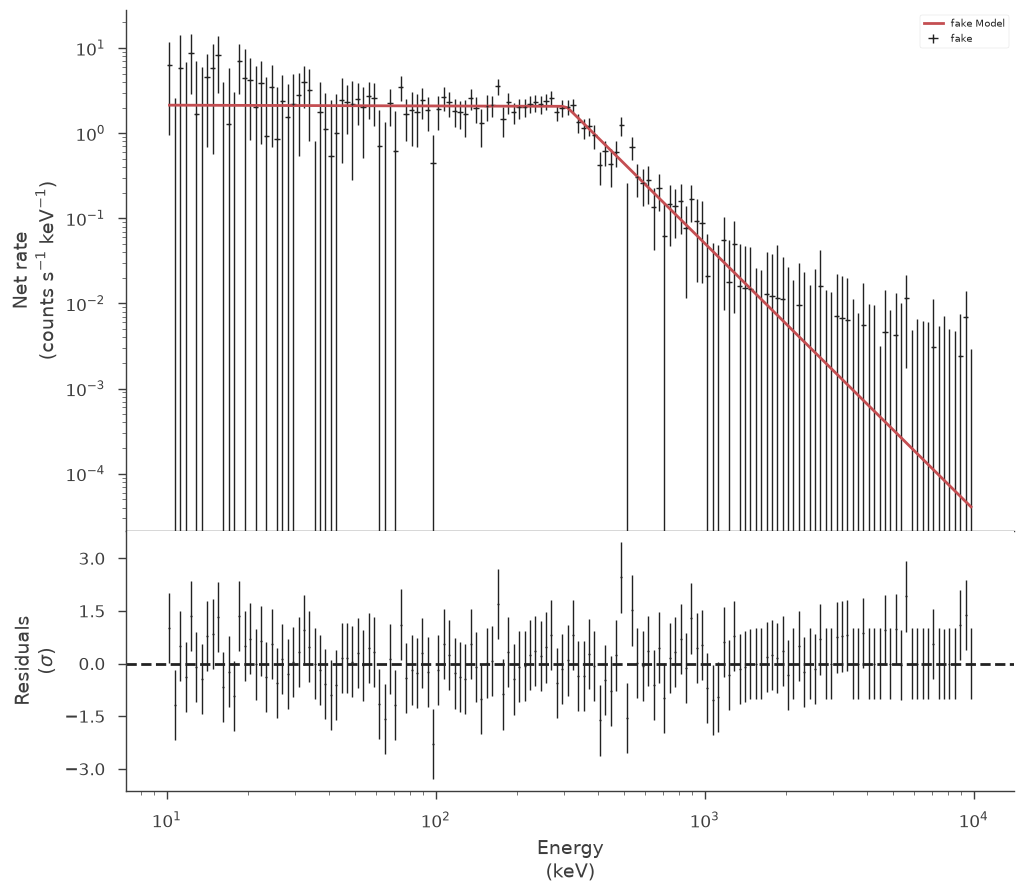
Our fit recovers the simulated parameters. However, we should have binned the spectrum up such that there is at least one background count per spectral bin for the profile to be valid.
[6]:
spectrum_generator.rebin_on_background(1)
spectrum_generator.view_count_spectrum()
_ = jl_profile.fit()
_ = spectrum_generator.display_model(step=False)
Best fit values:
| result | unit | |
|---|---|---|
| parameter | ||
| source.spectrum.main.Broken_powerlaw.K | 2.14 -0.15 +0.16 | 1 / (keV s cm2) |
| source.spectrum.main.Broken_powerlaw.xb | (3.00 -0.11 +0.12) x 10^2 | keV |
| source.spectrum.main.Broken_powerlaw.alpha | (5 +/- 8) x 10^-2 | |
| source.spectrum.main.Broken_powerlaw.beta | -3.05 +/- 0.15 |
Correlation matrix:
| 1.00 | -0.64 | 0.77 | 0.02 |
| -0.64 | 1.00 | -0.49 | -0.56 |
| 0.77 | -0.49 | 1.00 | 0.01 |
| 0.02 | -0.56 | 0.01 | 1.00 |
Values of -log(likelihood) at the minimum:
| -log(likelihood) | |
|---|---|
| fake | 307.916769 |
| total | 307.916769 |
Values of statistical measures:
| statistical measures | |
|---|---|
| AIC | 624.109401 |
| BIC | 635.876080 |

Modeling the background
Now let’s try to model the background assuming we know that the background is a power law with a Gaussian line. We can extract a background plugin from the data by passing the original plugin to a classmethod of spectrum like.
[7]:
# extract the background from the spectrum plugin.
# This works for OGIPLike plugins as well, though we could easily also just read
# in a bakcground PHA
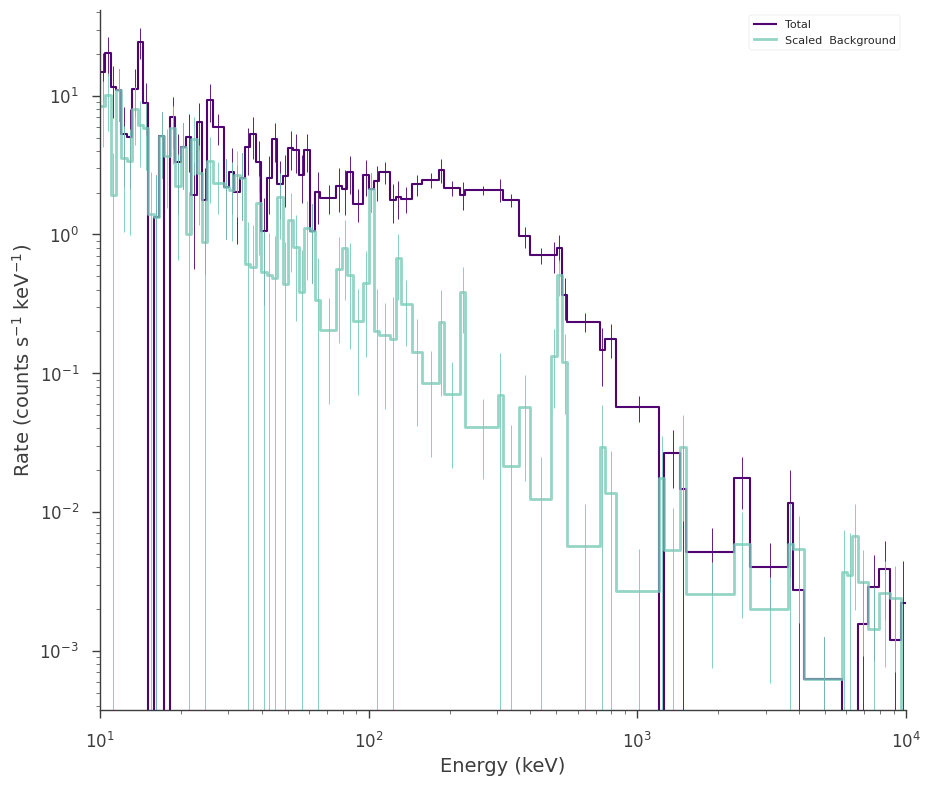
background_plugin = SpectrumLike.from_background("bkg", spectrum_generator)
This constructs a new plugin with only the observed background so that we can first model it.
[8]:
background_plugin.view_count_spectrum()
[8]:
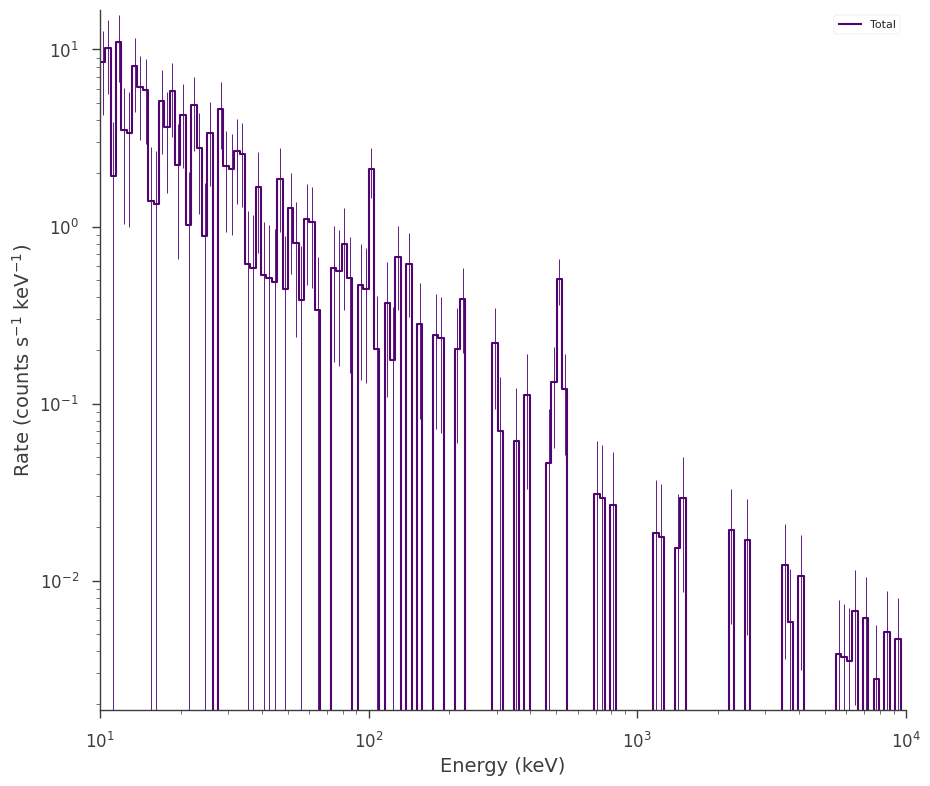
We now construct our background model and fit it to the data. Let’s assume we know that the line occurs at 511 keV, but we are unsure of its strength an width. We do not need to bin the data up because we are using a simple Poisson likelihood which is valid even when we have zero counts Cash (1979).
[9]:
# instance the spectrum setting the line's location to 511
bkg_spectrum = Powerlaw(piv=100) + Gaussian(F=50, mu=511)
# setup model parameters
# fix the line's location
bkg_spectrum.mu_2.fix = True
# nice parameter bounds
bkg_spectrum.K_1.bounds = (1e-4, 10)
bkg_spectrum.F_2.bounds = (0.0, 1000)
bkg_spectrum.sigma_2.bounds = (2, 30)
ps_bkg = PointSource("bkg", 0, 0, spectral_shape=bkg_spectrum)
bkg_model = Model(ps_bkg)
jl_bkg = JointLikelihood(bkg_model, DataList(background_plugin))
_ = jl_bkg.fit()
_ = background_plugin.display_model(
step=False, data_color="#1A68F0", model_color="#FF9700"
)
We have set the min_value of composite.K_1 to 1e-99 because there was a postive transform
The current value of the parameter sigma_2 (1.0) was below the new minimum 2.0.
The current value of the parameter sigma_2 (1.0) was below the new minimum 2.0.
Best fit values:
| result | unit | |
|---|---|---|
| parameter | ||
| bkg.spectrum.main.composite.K_1 | (2.82 -0.21 +0.23) x 10^-1 | 1 / (keV s cm2) |
| bkg.spectrum.main.composite.index_1 | -1.35 +/- 0.05 | |
| bkg.spectrum.main.composite.F_2 | (2.5 +/- 0.5) x 10 | 1 / (s cm2) |
| bkg.spectrum.main.composite.sigma_2 | (1.01 +/- 0.21) x 10 | keV |
Correlation matrix:
| 1.00 | 0.08 | -0.04 | -0.04 |
| 0.08 | 1.00 | -0.04 | -0.03 |
| -0.04 | -0.04 | 1.00 | 0.19 |
| -0.04 | -0.03 | 0.19 | 1.00 |
Values of -log(likelihood) at the minimum:
| -log(likelihood) | |
|---|---|
| bkg | 197.151886 |
| total | 197.151886 |
Values of statistical measures:
| statistical measures | |
|---|---|
| AIC | 402.579634 |
| BIC | 414.346313 |
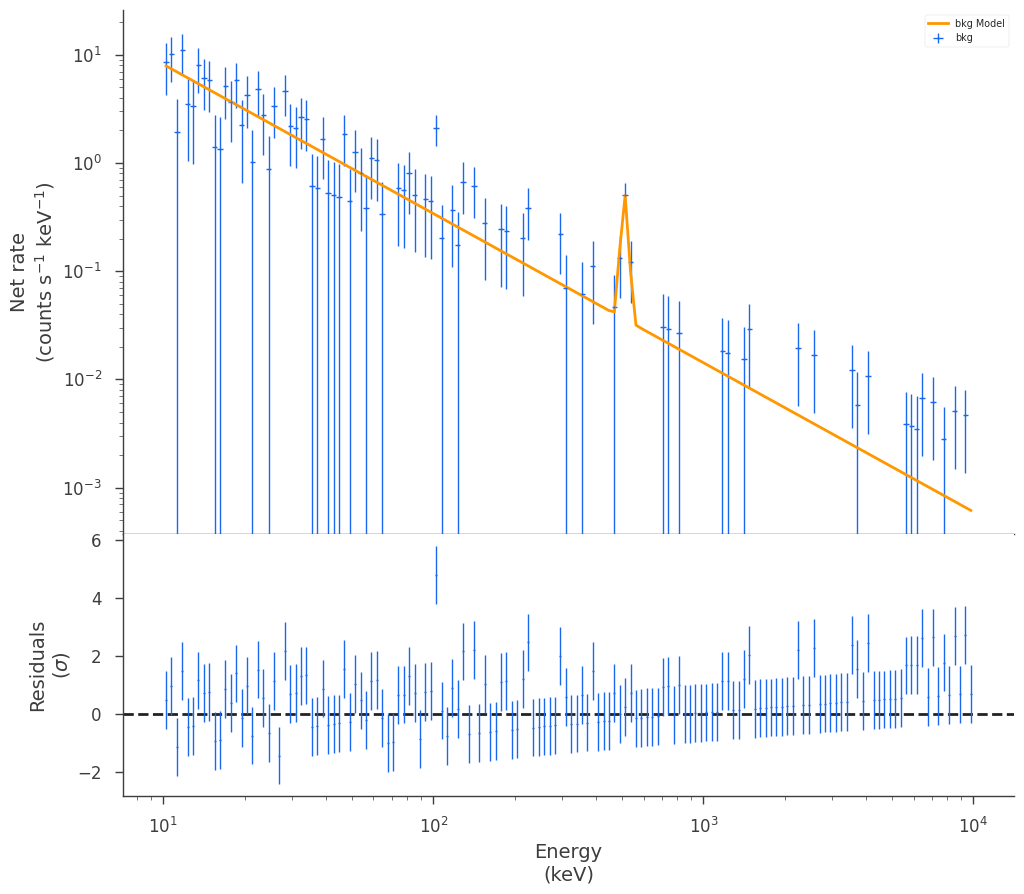
We now have a model and estimate for the background which we can use when fitting with the source spectrum. We now create a new plugin with just the total observation and pass our background plugin as the background argument.
[10]:
modeled_background_plugin = SpectrumLike(
"full",
# here we use the original observation
observation=spectrum_generator.observed_spectrum,
# we pass the background plugin as the background!
background=background_plugin,
)
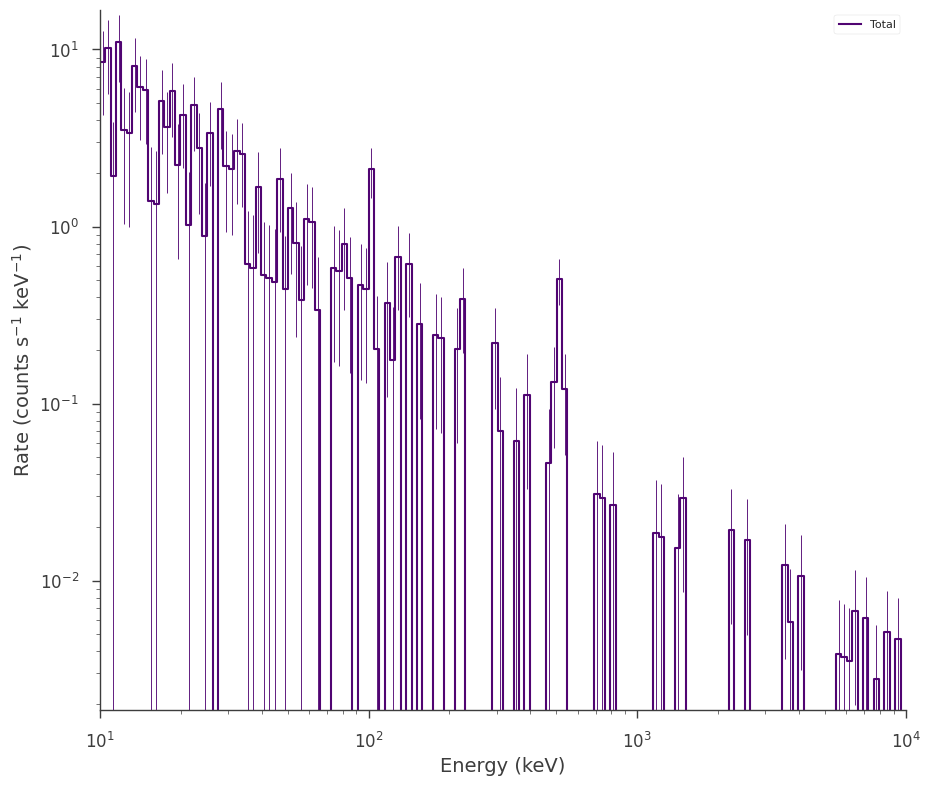
When we look at out count spectrum now, we will see the predicted background, rather than the measured one:
[11]:
modeled_background_plugin.view_count_spectrum()
[11]:
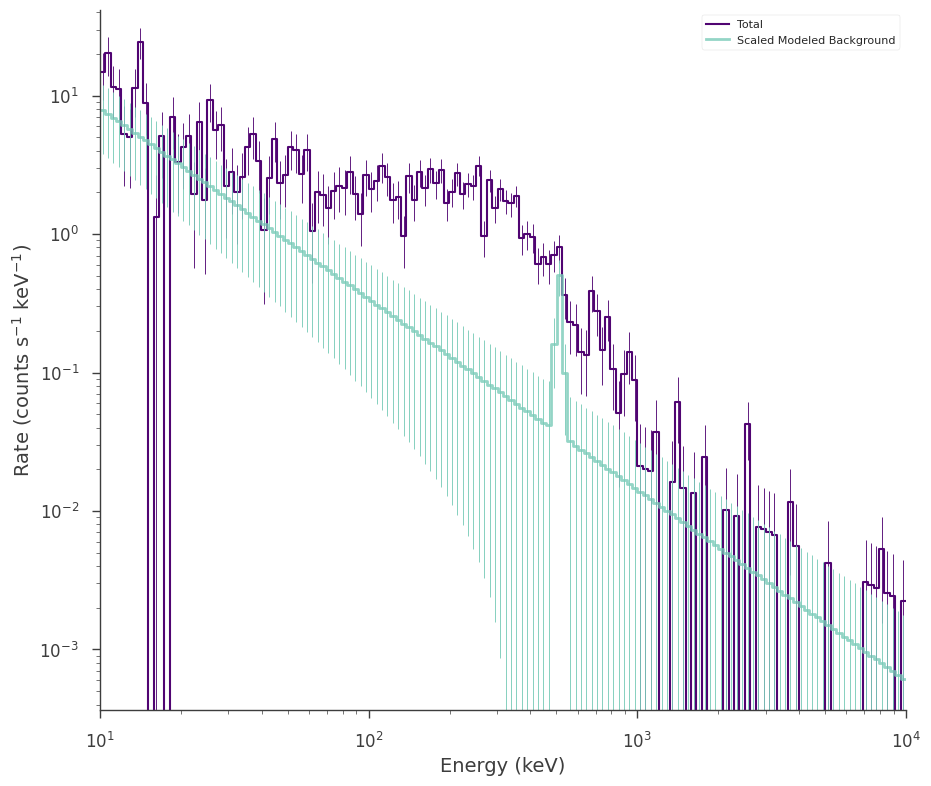
Now we simply fit the spectrum as we did in the profiled case. The background plugin’s parameters are stored in our new plugin as nuissance parameters:
[12]:
modeled_background_plugin.nuisance_parameters
[12]:
OrderedDict([('cons_full',
Parameter cons_full = 1.0 []
(min_value = 0.8, max_value = 1.2, delta = 0.05, free = False)),
('bkg_bkg_position_ra_full',
Parameter ra = 0.0 [deg]
(min_value = 0.0, max_value = 360.0, delta = 0.1, free = False)),
('bkg_bkg_position_dec_full',
Parameter dec = 0.0 [deg]
(min_value = -90.0, max_value = 90.0, delta = 0.1, free = False)),
('bkg_bkg_spectrum_main_composite_K_1_full',
Parameter K_1 = 0.2816278592002158 [1 / (keV s cm2)]
(min_value = 0.0001, max_value = 10.0, delta = 0.1, free = True)),
('bkg_bkg_spectrum_main_composite_piv_1_full',
Parameter piv_1 = 100.0 [keV]
(min_value = None, max_value = None, delta = 0.1, free = False)),
('bkg_bkg_spectrum_main_composite_index_1_full',
Parameter index_1 = -1.3506588308193588 []
(min_value = -10.0, max_value = 10.0, delta = 0.20099999999999998, free = True)),
('bkg_bkg_spectrum_main_composite_F_2_full',
Parameter F_2 = 25.490944804503307 [1 / (s cm2)]
(min_value = 0.0, max_value = 1000.0, delta = 0.1, free = True)),
('bkg_bkg_spectrum_main_composite_mu_2_full',
Parameter mu_2 = 511.0 [keV]
(min_value = None, max_value = None, delta = 0.1, free = False)),
('bkg_bkg_spectrum_main_composite_sigma_2_full',
Parameter sigma_2 = 10.148714303178831 [keV]
(min_value = 2.0, max_value = 30.0, delta = 0.1, free = True)),
('bkg_cons_bkg_full',
Parameter cons_bkg = 1.0 []
(min_value = 0.8, max_value = 1.2, delta = 0.05, free = False))])
and the fitting engine will use them in the fit. The parameters will still be connected to the background plugin and its model and thus we can free/fix them there as well as set priors on them.
[13]:
# instance the source model... the background plugin has it's model already specified
bpl = Broken_powerlaw(piv=300, xb=500)
bpl.K.bounds = (1e-5, 1e1)
bpl.xb.bounds = (1e1, 1e4)
ps_src = PointSource("source", 0, 0, bpl)
src_model = Model(ps_src)
jl_src = JointLikelihood(src_model, DataList(modeled_background_plugin))
_ = jl_src.fit()
We have set the min_value of Broken_powerlaw.K to 1e-99 because there was a postive transform
We have set the min_value of Broken_powerlaw.xb to 1e-99 because there was a postive transform
Best fit values:
| result | unit | |
|---|---|---|
| parameter | ||
| source.spectrum.main.Broken_powerlaw.K | 2.15 -0.15 +0.16 | 1 / (keV s cm2) |
| source.spectrum.main.Broken_powerlaw.xb | (2.99 -0.11 +0.12) x 10^2 | keV |
| source.spectrum.main.Broken_powerlaw.alpha | (5 +/- 8) x 10^-2 | |
| source.spectrum.main.Broken_powerlaw.beta | -3.08 +/- 0.17 | |
| K_1 | (3.03 +/- 0.32) x 10^-1 | 1 / (keV s cm2) |
| index_1 | -1.34 +/- 0.04 | |
| F_2 | (2.9 +/- 0.5) x 10 | 1 / (s cm2) |
| sigma_2 | (1.53 +/- 0.24) x 10 | keV |
Correlation matrix:
| 1.00 | -0.62 | 0.76 | 0.05 | 0.14 | -0.20 | -0.00 | -0.00 |
| -0.62 | 1.00 | -0.48 | -0.60 | -0.03 | 0.23 | -0.07 | -0.05 |
| 0.76 | -0.48 | 1.00 | 0.03 | 0.36 | -0.29 | -0.00 | -0.00 |
| 0.05 | -0.60 | 0.03 | 1.00 | -0.19 | -0.32 | -0.04 | -0.03 |
| 0.14 | -0.03 | 0.36 | -0.19 | 1.00 | 0.04 | -0.01 | -0.01 |
| -0.20 | 0.23 | -0.29 | -0.32 | 0.04 | 1.00 | 0.00 | 0.00 |
| -0.00 | -0.07 | -0.00 | -0.04 | -0.01 | 0.00 | 1.00 | 0.28 |
| -0.00 | -0.05 | -0.00 | -0.03 | -0.01 | 0.00 | 0.28 | 1.00 |
Values of -log(likelihood) at the minimum:
| -log(likelihood) | |
|---|---|
| full | 517.365487 |
| total | 517.365487 |
Values of statistical measures:
| statistical measures | |
|---|---|
| AIC | 1051.752251 |
| BIC | 1074.816056 |
[14]:
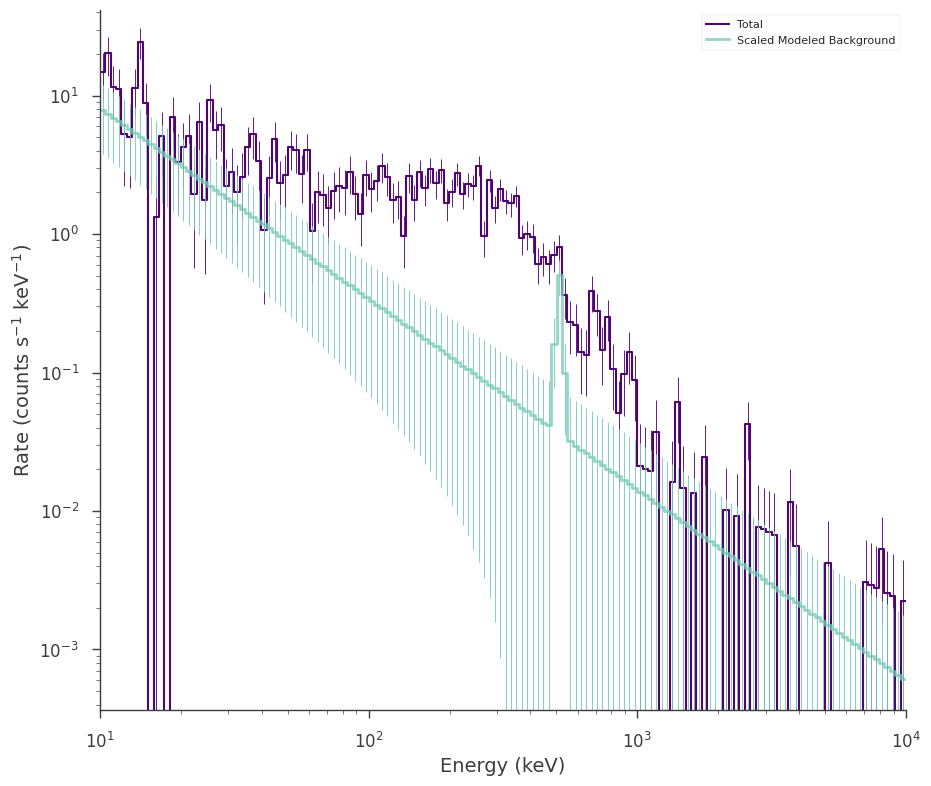
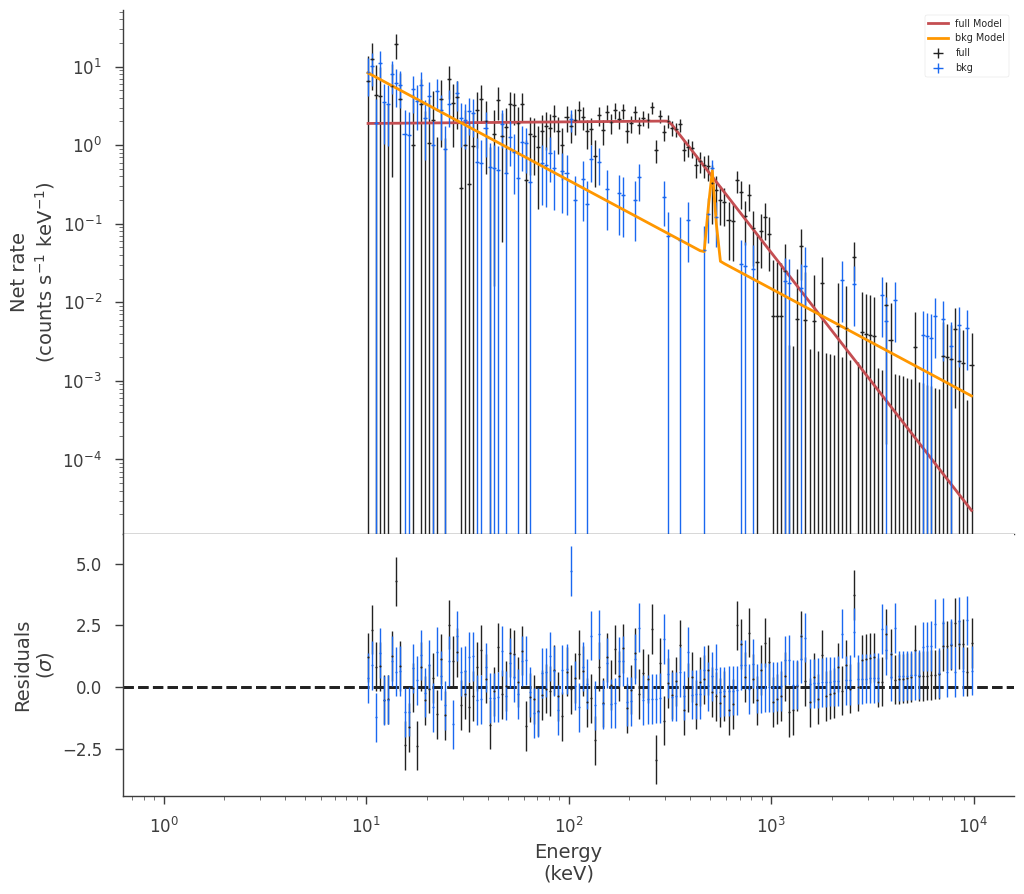
# over plot the joint background and source fits
fig = modeled_background_plugin.display_model(step=False)
_ = background_plugin.display_model(
data_color="#1A68F0", model_color="#FF9700", model_subplot=fig.axes, step=False
)
[ ]: