Quickstart¶
In this simple example we will generate some simulated data, and fit them with 3ML.
Let’s start by generating our dataset:
[1]:
import warnings
warnings.simplefilter("ignore")
import numpy as np
np.seterr(all="ignore")
[1]:
{'divide': 'warn', 'over': 'warn', 'under': 'ignore', 'invalid': 'warn'}
[2]:
%%capture
from threeML import *
[3]:
from jupyterthemes import jtplot
%matplotlib inline
jtplot.style(context="talk", fscale=1, ticks=True, grid=False)
silence_warnings()
set_threeML_style()
[4]:
# Let's generate some data with y = Powerlaw(x)
gen_function = Powerlaw()
# Generate a dataset using the power law, and a
# constant 30% error
x = np.logspace(0, 2, 50)
xyl_generator = XYLike.from_function(
"sim_data", function=gen_function, x=x, yerr=0.3 * gen_function(x)
)
y = xyl_generator.y
y_err = xyl_generator.yerr
We can now fit it easily with 3ML:
[5]:
fit_function = Powerlaw()
xyl = XYLike("data", x, y, y_err)
parameters, like_values = xyl.fit(fit_function)
Best fit values:
| result | unit | |
|---|---|---|
| parameter | ||
| source.spectrum.main.Powerlaw.K | (9.6 -0.8 +0.9) x 10^-1 | 1 / (cm2 keV s) |
| source.spectrum.main.Powerlaw.index | -2.008 +/- 0.033 |
Correlation matrix:
| 1.00 | -0.86 |
| -0.86 | 1.00 |
Values of -log(likelihood) at the minimum:
| -log(likelihood) | |
|---|---|
| data | 23.314999 |
| total | 23.314999 |
Values of statistical measures:
| statistical measures | |
|---|---|
| AIC | 50.885318 |
| BIC | 54.454045 |
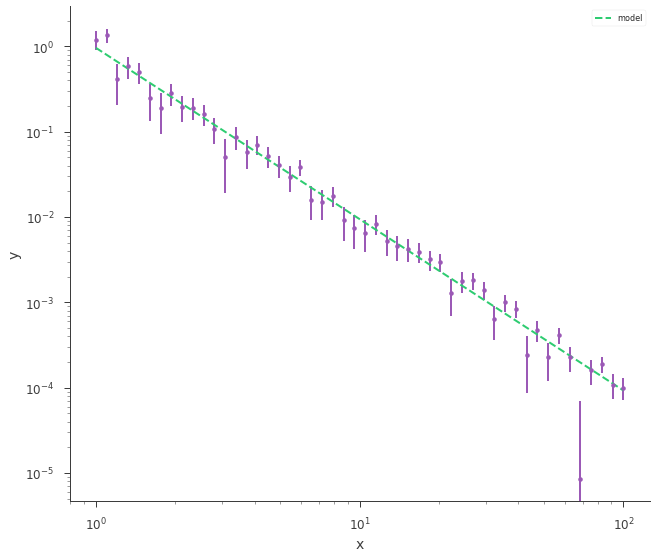
Plot data and model:
[6]:
fig = xyl.plot(x_scale="log", y_scale="log")
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Generic family 'sans-serif' not found because none of the following families were found: Helvetica
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Generic family 'sans-serif' not found because none of the following families were found: Helvetica
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Generic family 'sans-serif' not found because none of the following families were found: Helvetica
Compute the goodness of fit using Monte Carlo simulations (NOTE: if you repeat this exercise from the beginning many time, you should find that the quantity “gof” is a random number distributed uniformly between 0 and 1. That is the expected result if the model is a good representation of the data)
[7]:
gof, all_results, all_like_values = xyl.goodness_of_fit()
print("The null-hypothesis probability from simulations is %.2f" % gof["data"])
The null-hypothesis probability from simulations is 0.55
The procedure outlined above works for any distribution for the data (Gaussian or Poisson). In this case we are using Gaussian data, thus the log(likelihood) is just half of a \(\chi^2\). We can then also use the \(\chi^2\) test, which gives a close result without performing simulations:
[8]:
import scipy.stats
# Compute the number of degrees of freedom
n_dof = len(xyl.x) - len(fit_function.free_parameters)
# Get the observed value for chi2
# (the factor of 2 comes from the fact that the Gaussian log-likelihood is half of a chi2)
obs_chi2 = 2 * like_values["-log(likelihood)"]["data"]
theoretical_gof = scipy.stats.chi2(n_dof).sf(obs_chi2)
print("The null-hypothesis probability from theory is %.2f" % theoretical_gof)
The null-hypothesis probability from theory is 0.53
There are however many settings where a theoretical answer, such as the one provided by the \(\chi^2\) test, does not exist. A simple example is a fit where data follow the Poisson statistic. In that case, the MC computation can provide the answer.