Random Variates
When we perform a fit or load and analysis result, the parmeters of our model become distributions in the AnalysisResults object. These are actaully instantiactions of the RandomVaraiates class.
While we have covered most of the functionality of RandomVariates in the AnalysisResults section, we want to highlight a few of the details here.
[1]:
import warnings
warnings.simplefilter("ignore")
import numpy as np
np.seterr(all="ignore")
[1]:
{'divide': 'warn', 'over': 'warn', 'under': 'ignore', 'invalid': 'warn'}
[2]:
%%capture
import matplotlib.pyplot as plt
from threeML import *
[3]:
from jupyterthemes import jtplot
%matplotlib inline
jtplot.style(context="talk", fscale=1, ticks=True, grid=False)
set_threeML_style()
silence_warnings()
Let’s load back our fit of the line + gaussian from the AnalysisResults section.
[4]:
ar = load_analysis_results("test_mle.fits")
When we display our fit, we can see the parameter paths of the model. What if we want specific information on a parameter(s)?
[5]:
ar.display()
Best fit values:
| result | unit | |
|---|---|---|
| parameter | ||
| fake.spectrum.main.composite.a_1 | 1.82 +/- 0.11 | 1 / (keV s cm2) |
| fake.spectrum.main.composite.b_1 | (3 +/- 4) x 10^-3 | 1 / (s cm2 keV2) |
| fake.spectrum.main.composite.F_2 | (2.8 +/- 0.4) x 10 | 1 / (s cm2) |
| fake.spectrum.main.composite.mu_2 | (2.518 +/- 0.012) x 10 | keV |
| fake.spectrum.main.composite.sigma_2 | (8.7 +/- 0.9) x 10^-1 | keV |
Correlation matrix:
| 1.00 | -0.85 | -0.04 | 0.01 | -0.05 |
| -0.85 | 1.00 | 0.00 | -0.01 | -0.00 |
| -0.04 | 0.00 | 1.00 | -0.21 | 0.02 |
| 0.01 | -0.01 | -0.21 | 1.00 | -0.16 |
| -0.05 | -0.00 | 0.02 | -0.16 | 1.00 |
Values of -log(likelihood) at the minimum:
| -log(likelihood) | |
|---|---|
| sim_data | 36.717407 |
| total | 36.717407 |
Values of statistical measures:
| statistical measures | |
|---|---|
| AIC | 84.798450 |
| BIC | 92.994929 |
Let’s take a look at the normalization of the gaussian. To access the parameter, we take the parameter path, and we want to get the variates:
[6]:
norm = ar.get_variates("fake.spectrum.main.composite.F_2")
Now, norm is a RandomVariate.
[7]:
type(norm)
[7]:
threeML.random_variates.RandomVariates
This is essentially a wrapper around numpy NDArray with a few added properties. It is an array of samples. In the MLE case, they are samples from the covariance matrix (this is not at all a marginal distribution, but the parameter “knows” about the entire fit, i.e., it is not a profile) and in the Bayesian case, these are samples from the posterior (this is a marginal).
The output representation for an RV are its 68% equal-tail and HPD uncertainties.
[8]:
norm
[8]:
equal-tail: (2.8 +/- 0.4) x 10, hpd: (2.8 +/- 0.4) x 10
We can access these directly, and to any desired confidence level.
[9]:
norm.equal_tail_interval(cl=0.95)
[9]:
(20.226710887565133, 35.80157698748687)
[10]:
norm.highest_posterior_density_interval(cl=0.5)
[10]:
(25.39353228385188, 30.71257712787364)
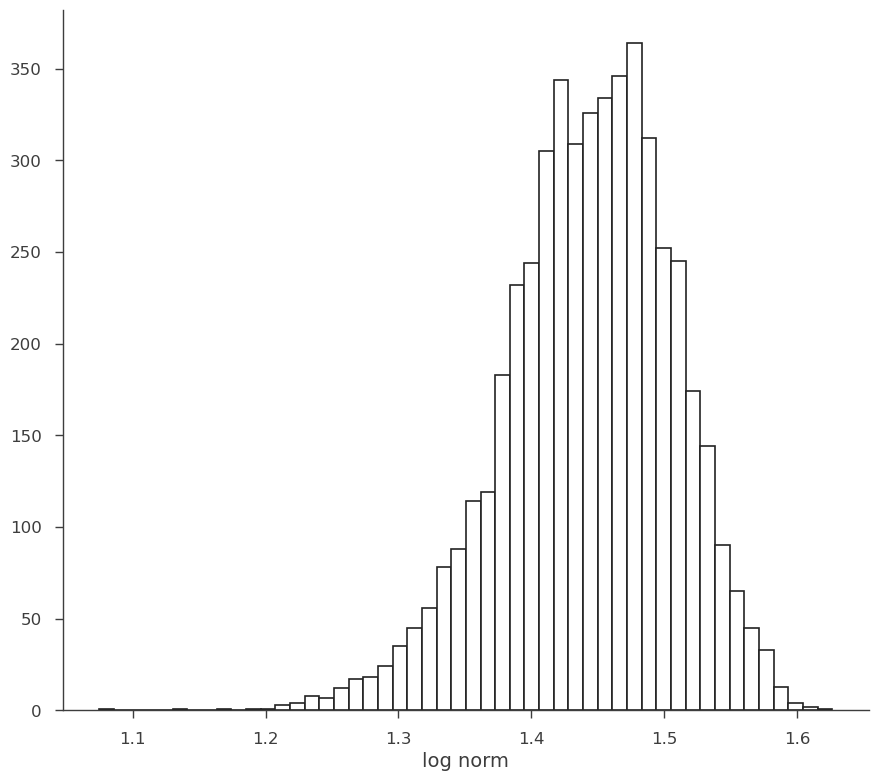
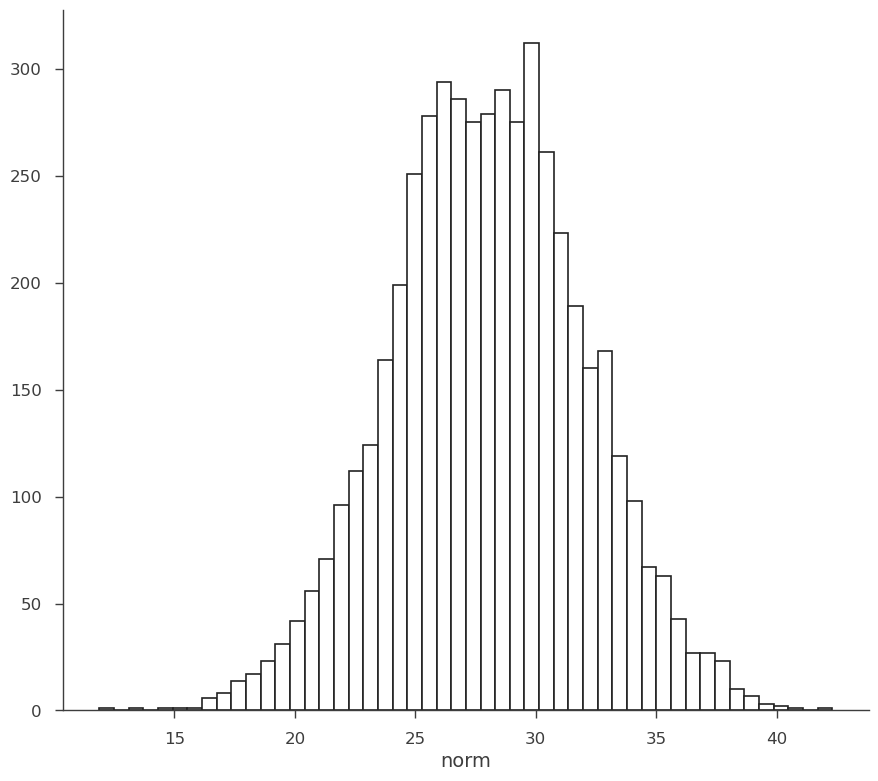
As stated above, the RV is made from samples. We can histogram them to show this explicitly.
[11]:
fig, ax = plt.subplots()
ax.hist(norm.samples, bins=50, ec="k", fc="w", lw=1.2)
ax.set_xlabel("norm")
[11]:
Text(0.5, 0, 'norm')
We can easily transform the RV through propagation.
[12]:
log_norm = np.log10(norm)
log_norm
[12]:
equal-tail: 1.45 +/- 0.06, hpd: 1.45 -0.05 +0.07
[13]:
fig, ax = plt.subplots()
ax.hist(log_norm.samples, bins=50, ec="k", fc="w", lw=1.2)
ax.set_xlabel("log norm")
[13]:
Text(0.5, 0, 'log norm')